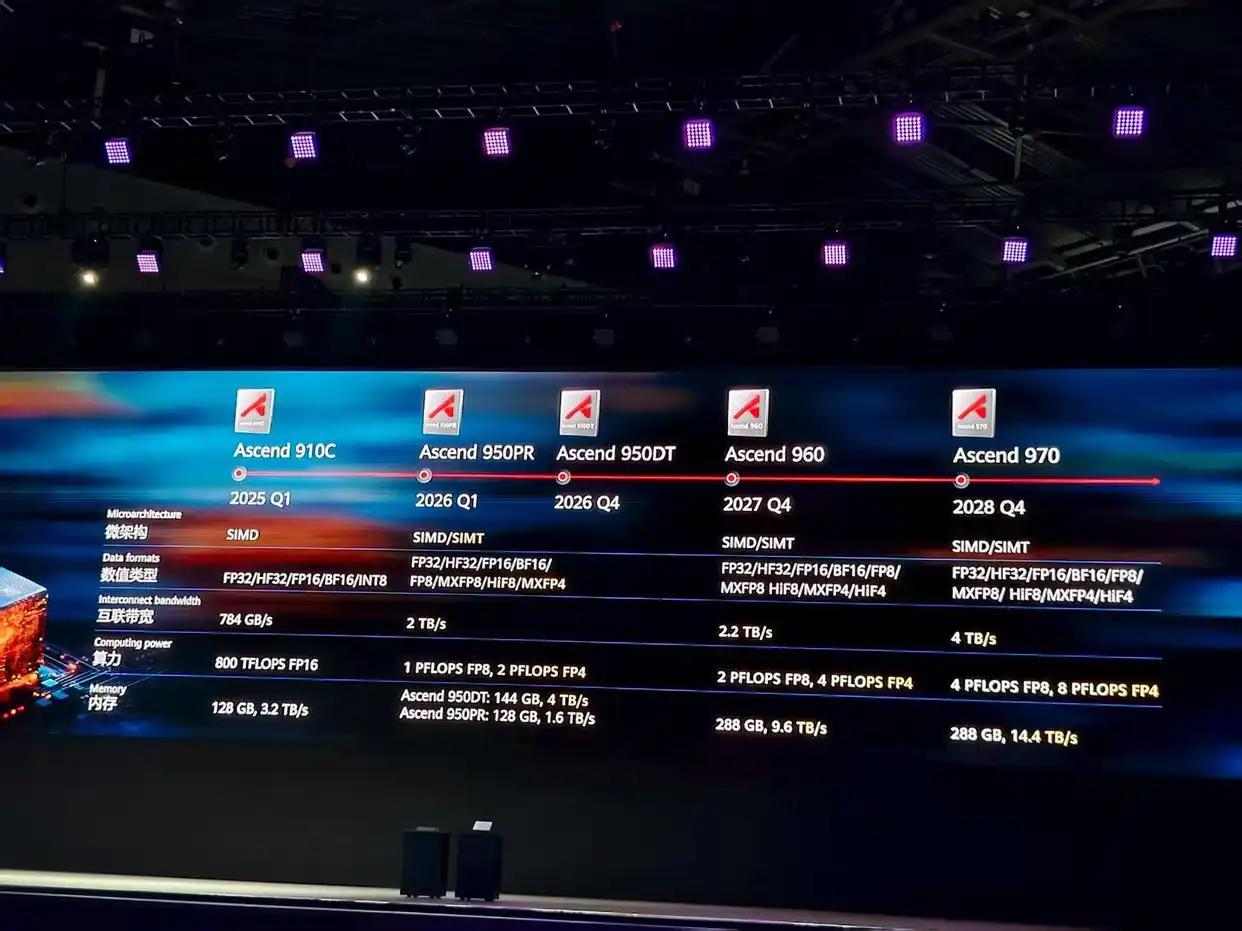
此前,华为已经发布了Cloud Matrix 384超节点,通过6912个LPO光模块实现光互联将384张GPU同时连接在一起。这次发布会上,华为称CM384已经累计部署300+套,服务20+客户。华为即将推出的 Atlas 950 SuperPoD 与 Atlas 960 SuperPoD 两款超节点,分别支持 8,000 卡与 1.5 万卡的大规模并行计算,进一步刷新超节点的规模和算力上限,似乎已与传统 “集群” 概念高度趋近。
作为长期跟踪光通信的产业媒体,光纤在线更关心:超节点、灵衢总线对光通信产业的影响有几何? 华为的最新AI芯片又有哪些创新?对比英伟达的方案又如何?带着这些问题,我们回顾了徐总的演讲,并与大家分享几个关注点。
超节点与集群的边界探索
“超节点(SuperPod)” 这一概念由英伟达率先提出,其技术本质是通过纵向扩展(Scale Up) 模式,将大量计算芯片紧密耦合,形成单一的高速互连域,从而高效解决大规模算力集群中芯片协同调度的关键难题。
徐直军在发布会上强调:超节点成为AI基础设施建设新常态。
从产业应用需求来看,超节点的规模升级也与全球及国内算力需求规模相对契合。据和弦产研C&C调查,全球范围内,OpenAI、微软、xAI、Meta 等头部科技公司已纷纷启动超 10 万卡规模 GPU 集群的建设;而在国内,随着 2024 年智算中心建设进入快车道,万卡级集群的数据中心项目正加速落地,“万卡规模” 已成为匹配国内当前 AI 算力需求的主流选择。在这一点上,看起来华为新一代超节点的算力规模足以匹配时下国内算力需求的规模。
而对比英伟达和华为,两家公司在超节点的具体互联方式和规模上,呈现出显著的差异化特征:
• 英伟达:铜互联为核心,光互联为补充
英伟达的超节点(Scale Up)长期以铜互联为核心技术方案。例如其推出的 NVL72 产品,便是将 72 个 GPU 集成在单个机柜内,GPU 之间通过短距离铜缆实现高速连接;而更高规模的 NVL576,则是通过高速 InfiniBand 或以太网,将 8 个 NVL72 机柜进行 “横向扩展(Scale-out)”,以光互联方式组建为完整集群。可见在英伟达的架构中,超节点内部以铜互联为主,多超节点间的集群化扩展才依赖光互联。
• 华为:全光互联,突破超节点规模边界
华为则聚焦于以光互联为核心的技术路线,不断构建规模更庞大的超节点。在发布会上,华为进一步提出 “超节点 + 集群” 的概念,持续破解中国AI算力瓶颈,且全链路采用光互联技术实现连接。但在光纤在线看来,华为正通过扩大单个超节点的算力规模,逐步模糊传统 “超节点” 与 “集群” 的边界,其打造的超节点,本质上已具备数据中心集群的核心能力。
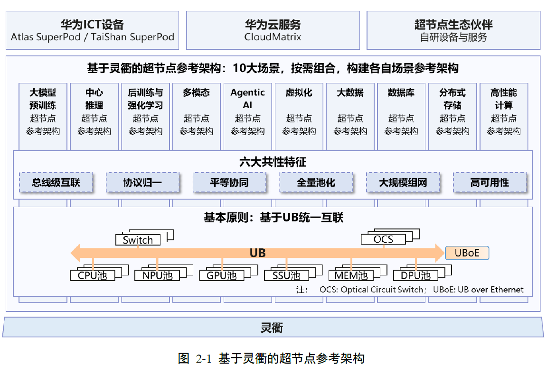
灵衢协议:全光互联架构下支持CPU与GPU协同
在超节点互联协议上,华为推出的灵衢(UnifiedBus,简称 UB)新型计算系统架构,构建了支持 CPU、NPU、GPU、存储(MEM)与交换机(Switch)等多元组件资源池化与平等协同的技术底座,其核心突破在于通过全光互联实现各类算力单元的高效调度。
这一架构选择,进一步拉大了华为与英伟达在超节点算力支持体系上的差异,也直接决定了两者超节点在应用场景上的核心定位。
从英伟达的技术布局来看,其超节点始终以GPU 互联为核心,聚焦于人工智能训练、高性能计算等算力密集型场景。无论是此前的 NVL72、NVL576,还是即将推出的NVL144,其架构设计均通过优化 GPU 间的互连效率提升智算能力,并未将通用计算的 CPU 纳入超节点的核心集成范畴。这一设计使其超节点在纯智算场景中具备极强的专项性能。
而华为自 CM384 超节点起,便确立了“GPU+CPU 协同”的技术路线。如CM384集成 384 个昇腾 910C NPU 和 192 个鲲鹏 920 CPU,通过光互联技术实现两类算力卡的高效协同。这一设计使得华为超节点既能满足人工智能、大模型训练等智算需求,又能支撑数据处理、业务逻辑运算等通用计算场景,适配多元化的企业级应用需求,尤其在需要两类算力协同的复杂业务场景中,展现出更强的综合适配性。
突破内存瓶颈:硬件升级 or 硬件协作
随着生成式 AI 迈向规模化应用,不仅术要考虑算力芯片的“峰值算力”,更要关注内存的带宽和功耗的约束,内存瓶颈已经成为制约 AI 产业持续发展的核心症结。而华为和英伟达在硬件升级和技术协同方面均有策重点。
硬件升级:高带宽内存(HBM)成为高端算力芯片的核心竞争力。英伟达的 H100 芯片凭借4TB/s 的 HBM 带宽长期垄断高端市场;基于 Hopper 架构的 H20 芯片,不仅搭载 96GB HBM3 内存,更延续了 4.0TB/s 的高带宽表现,为大规模 AI 计算提供支撑。反观华为这次发布的昇腾 950 系列,在HBM 技术上实现关键突破:不仅将自研 HBM 带宽提升至 4TB/s,更将内存容量扩容至 144GB。昇腾 950DT 更是搭载了 HiZQ 2.0 自研 HBM 技术,采用128B 精细粒度内存访问设计(较上一代效率提升 4 倍),让 AI 芯片能够更精准、高效地处理非结构化数据,从硬件层面大幅降低数据读取延迟。
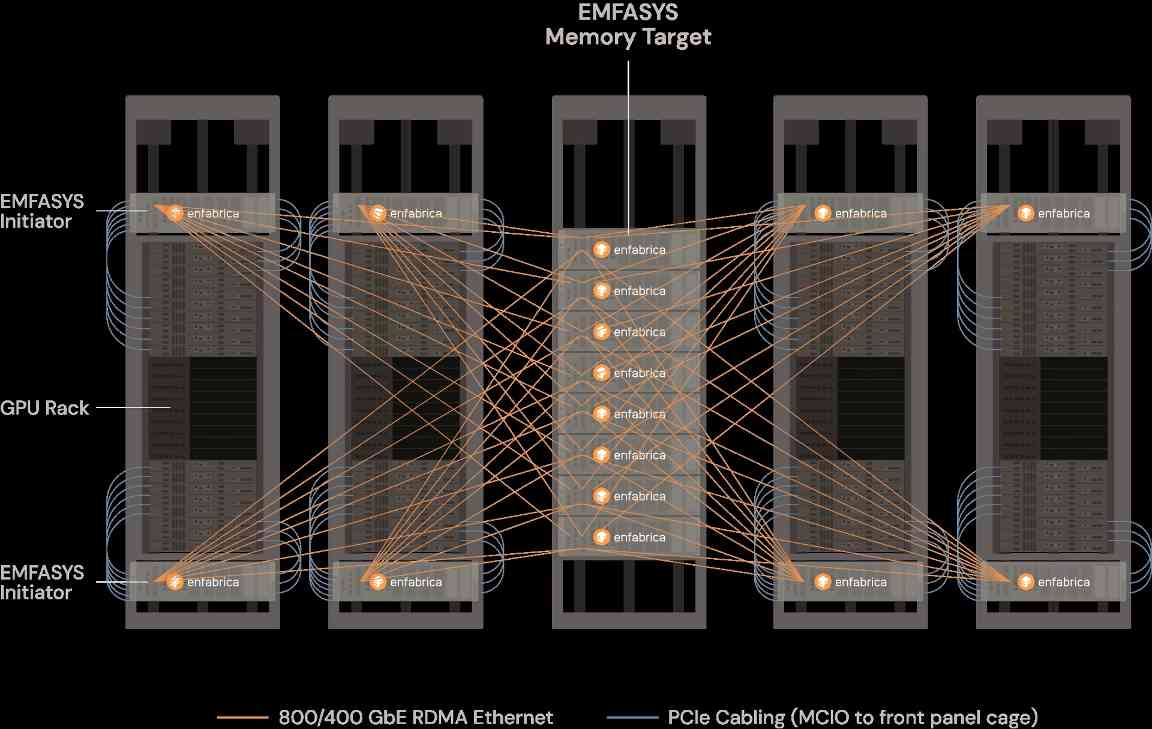
无独有偶,几乎在同一时间,英伟达宣布斥资超 9 亿美元吸纳人工智能硬件初创公司 Enfabrica 的首席执行官 Rochan Sankar 及核心团队,并获得该公司的核心技术授权。Enfabrica 的技术核心正是解决 AI 集群的 “协同瓶颈”—— 通过弹性内存网络系统(EMFASYS)优化芯片间的数据传输架构,将成千上万颗计算芯片高效集成、协同运作,为破解 AI 内存瓶颈提供了极具创新性的解决方案。在 AI 集群中,若网络组件的响应速度滞后或成本效益失衡,即便单颗计算芯片性能强悍,也会因等待跨芯片数据传输而陷入闲置,造成巨额资源浪费。此次整合,正是英伟达为破解大规模 AI 集群 “协同效率” 难题的关键布局。
值得关注的是,在算力芯片的 “精度格式”层面,当前行业广泛采用的 FP16(半精度)与 FP8(8 位精度),通过牺牲部分精度,降低存储占用,减少数据传输量,换取存储与计算效率的显著提升。FP16 是 “精度与效率的均衡选择”,适用于对精度有一定要求的中端推理与轻量训练场景;FP8 则是 “效率优先的极致优化”,更适配超大规模 AI 推理的高并发需求。而华为自研的 HiF8 格式,在延续 FP8 高效特性的基础上,通过创新的动态点位域设计与锥形精度优化,将精度提升至接近 FP16 的水平,实现了 “低开销” 与 “高精度” 的双重突破,为 AI 计算提供了更灵活的精度选择。



