思科指出,当前AI训练集群的规模化部署已成为推动技术进步的关键动力,但随之而来的是对计算资源和网络带宽的巨大需求。传统的“纵向扩展”(Scale Up)和“横向扩展”(Scale Out)模式在应对AI工作负载时,面临着功耗激增、资源利用率低下以及跨地域互联效率不足等问题,AI计算必须通过连接多个数据中心来跨数据中心扩展,因此“Scale Across”方法至关重要。思科 Silicon One P200 是业界首款 51.2Tbps 全双工深度缓冲路由处理器,专为Scale Across 时代打造。

Silicon One P200:
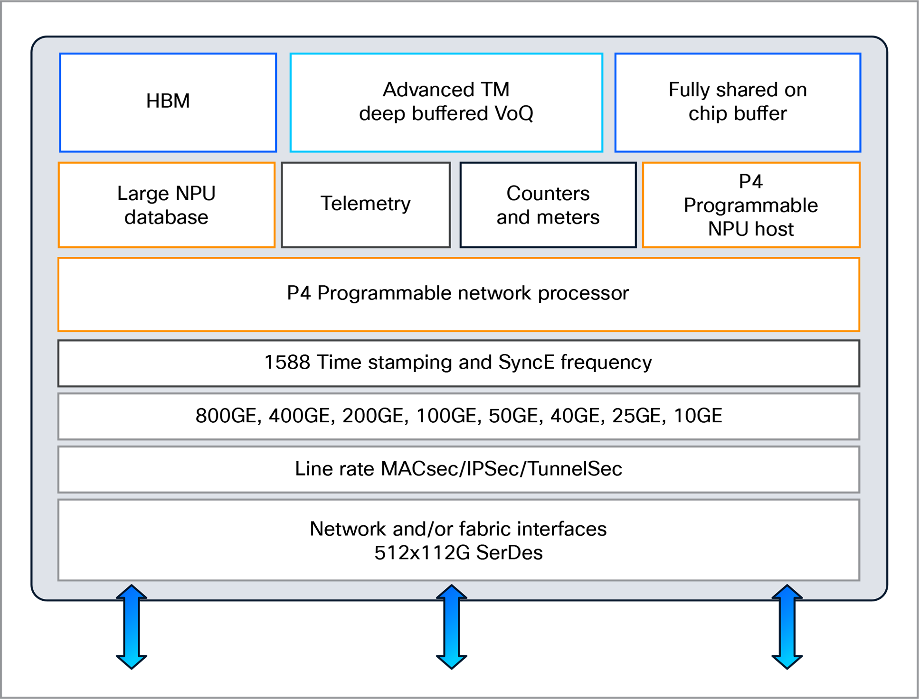
●带宽突破:单芯片提供51.2 Tbps全双工吞吐能力,支持64个800G端口,每秒可处理超过200亿个数据包。
●端口配置:集成了512个112G SerDes,每个SerDes都可以独立配置,支持从10GE到800Gbps的多种端口速率。
深度缓冲技术:完全共享片上缓冲区和大型外部数据包缓冲区,可动态分配资源吸收 AI 训练中的流量激增(如 GPU 间数据交互峰值),避免数据包丢失导致的重处理,减少算力浪费
●可编程性: P200基于思科Silicon One统一网络架构,具备高度可编程的“run-to-completion”数据包处理器和P4可编程能力。这意味着芯片能够根据实时网络需求进行调整,支持未来新兴网络协议和标准,无需频繁更换硬件即可持续升级。
●集成安全与遥测: 芯片在设计之初就考虑了数据和系统安全,内置了多重安全防护机制。此外,P200还支持丰富的遥测功能,如NetFlow、sFlow和带内遥测。
Cisco 8223 路由系统 :
思科 8223 充分利用思科 Silicon One 的融合架构,号称是业界唯一一款配备完全共享数据包缓冲区的 51.2 Tbps 深度缓冲路由器,其大容量和智能缓冲功能专为吸收 AI 训练负载共享带来的海量流量激增而设计,确保性能稳定并缓解网络拥塞。

●密度与能效:采用 3RU(机架单元)紧凑设计,在提供 51.2Tbps 全双工带宽的同时,功耗较上一代 Cisco 8804(10RU、57.6Tbps 模块化系统)降低约 65%,直接解决 AI 数据中心“电力约束”的核心瓶颈。

●多系统兼容:支持开源网络操作系统(NOS)如 SONiC,计划兼容思科传统 IOS XR 系统;同时,基于 P200 的 Cisco Nexus 9000 系列交换机将支持 NX-OS,实现路由-交换生态的无缝衔接。
●量产与客户验证:目前已开始向头部超大规模数据中心(Hyperscalers)出货,标志着 P200 从技术方案走向实际应用。

Cisco Silicon One P200 可以构建各种产品,涵盖固定外形路由器和交换机、模块化机箱路由器和交换机以及多 PB 级分解路由器和交换机。
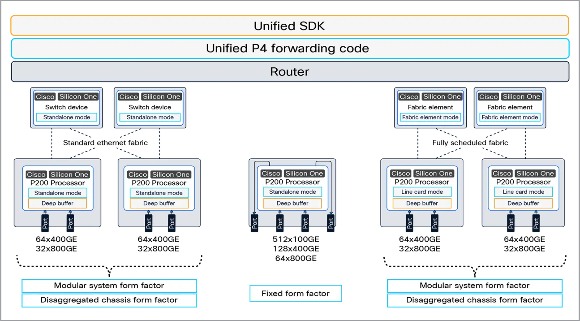
思科正通过一系列组合拳,在激烈的市场竞争中构建自己的护城河。
●强化核心竞争力: 巩固其在网络设备领域的领导地位,并将核心技术延伸至底层芯片设计,掌握更多主动权。
●抢占AI数据中心市场: AI数据中心是未来网络市场增长最快的领域之一。思科通过提供高性能、高能效且专为AI优化的网络解决方案,旨在成为这一市场的关键参与者。
●推动Scale Across愿景: P200芯片是思科Scale Across架构的核心,该架构旨在打破传统数据中心的物理边界,将分散的计算资源整合为统一的AI超级计算机,从而实现资源的最佳利用和AI工作负载的无缝分发。
●安全性与可观测性:思科将安全性深度融合到网络芯片中,并结合其收购Splunk后增强的可观测平台,提供了从芯片到应用的整体解决方案,这构成了其区别于纯硬件厂商的软实力。
思科P200芯片的发布,被市场普遍解读为对博通(Broadcom)等在数据中心网络芯片领域占据主导地位的厂商的有力挑战。长期以来,博通在交换芯片市场拥有强大的影响力,其产品广泛应用于各大云服务提供商和企业数据中心。英伟达(NVIDIA)也通过其InfiniBand和以太网解决方案,在AI/HPC网络领域占据重要地位。
思科此举意在通过自研芯片,提供差异化的解决方案,尤其是在AI数据中心互联这一新兴且高价值的市场。P200的优势在于其深度缓存、高能效以及为路由功能优化的设计,这与博通更侧重于交换功能的芯片有所不同。思科希望通过提供从芯片到系统的端到端解决方案,以及其在企业级网络市场的深厚积累,来赢得客户的青睐。
小结
思科Silicon One P200芯片的发布,是思科在AI时代下的一次重要战略部署。它不仅展示了思科在网络芯片领域的强大研发实力,更提供了一种应对AI数据中心网络挑战的创新解决方案。思科的AI之路已然打开局面,但未来依旧机遇与挑战并存。



