在Credo看来,无处不在的高速互联技术构成了AI智算时代“运力”的基础,并贯穿于整个AI智算系统之中——从基于XSR、UCIe等短距互联技术实现芯片内部(die-to-die)及HBM之间的横向扩展,到借助VSR、MR、LR等技术完成芯片间(chip-to-chip)、芯片至模组(chip-to-module)乃至背板级别的连接,再到通过高速网络实现设备间、机架间乃至跨数据中心的大规模互联,任何环节网络的延迟或带宽的瓶颈都会导致昂贵的GPU空闲等待, 因此高速互联技术始终是支撑AI智算系统高效运行的关键所在。
五大产品线战略布局,构建“三高三低”的差异化优势

在AI算力需求爆发的新时代,Credo凭借18年的探索和积累,形成了“三高三低”的差异化技术优势,覆盖SerDes IP、高速AEC、光DSP、Line Card和PCIe/CXL系列在内的五大产品线布局,持续为全球客户提供高性能、高可靠的互联解决方案。
三高:高带宽、高性能、高可靠性
●在高带宽方面,Credo的产品设计始终预留充足余量。例如,行业普遍将单波速率推至53G(基于50G基础),而Credo已实现56G、58G乃至64G;在单波100G代际,更进一步将行业标准的112G提升至128G,持续突破物理极限。
●在系统可靠性方面,Credo的方案相较同类对标产品,可提升两个数量级以上。
●在高性能方面,Credo十余年来死磕性能平衡,从功耗、工艺、成本、技术风险点多个维度着手,找到一个最佳的工艺点,使得产品特色越来越明显。 而在芯片层面,本着互助共赢的角度,Credo的 IP不仅用于自身,同时也向客户授权,把IP做成chiplet能够和客户的ASIC融合在一起,与客户一起从应用的角度,从芯片层面帮助客户解决运力问题。
三低:低功耗、低延迟、低成本
●低延迟在智算大规模组网中愈发关键,Credo通过优化架构与信号处理,显著降低传输时延,提升整体计算效率。
●除了低延迟,Credo更注重功耗和成本的优化。通过自研SerDes技术和定制化电路设计,在同等工艺节点制程下实现了节省30%功耗的优势。在大规模数据中心场景中,这意味着可以节省数兆瓦的电力,相当于增加数千颗GPU的算力。确保了其产品的长期竞争力,实现更具竞争力的成本结构。
Credo光产品销售与市场副总裁Chris Collins介绍说:通过持续的技术创新与产品演进,Credo致力于帮助客户突破互联瓶颈、提升运力效率,在日益激烈的全球AI网络竞争中抢占先机。
PCIe Gen 6:定义下一代Scale-Up互联
今年,Credo进一步拓展产品矩阵,推出针对Scale up架构的PCIe/CXL Retimer芯片,助力AI服务器实现纵向扩展。相较于当前业界主流的Gen 5方案,Credo率先推出PCIe Gen 6 Retimer,搭载自研SerDes技术,可根据客户链路需求,灵活连接CPU或交换机至更多GPU、SSD及其他存储设备,同时开发了一个叫PILOT的工具,用于实时监控全链路安全状态,大受客户欢迎。
首款Gen 6 Retimer采用7nm工艺,攻克了信号延迟与工艺适配等关键技术难点,并将Credo在以太网AEC领域的成熟经验成功迁移至PCIe产品线。支持最长7米传输距离,可连接数十个GPU,实现跨机柜级Scale up互联,有效解决高性能计算场景下的“运力”瓶颈。
众所周知,Credo基于自身Retimer的优势成就了AEC高速线缆在以太网络中的成功应用, Credo也推出了PCIe AEC产品。区别于以太网AEC,PCIe是更标准化的产品,但也会根据客户的需求去体现自身的性能特色。PCIe 更多的是实现Scale up上的扩展性,未来还有很多的技术和应用场景值得去探索,预计也将在明年市场需求会真正爆发。

光DSP性能优势:定制化设计实现功耗突破
随着AI技术的快速发展,全球范围内正在进行一场AI算力军备赛。据调研,全球已有超过11家企业在AI的年开支超过50亿美元,部分公司甚至超过1000亿美元。粗略计算,大公司针对AI数据中心的总投入规模已突破 5000 亿美元,而从英伟达财报来看,其数据中心业务中 16% 的收入来自网络而非 GPU,而这些网络开支主要应用AI智算的算力网络和通用计算网络。而这两种网络的架构并不尽相同,不同的架构需要不同的互联解决方案。
在通用计算中,更多网络互联用于面向用户的前端(front end)网络;而在AI智算网络中,增加了一个后端(back end)加速网络(Scale-Up),主要用于将多个GPU 连接在一起,组成一台大型计算机协同工作,而这正是大模型训练的实现方式:每一块 GPU 都与其他 GPU 进行通信并共同运作。正因为 AI 网络包含这样两个独立网络,其所需的光收发器数量,至少是通用计算网络的2-10倍。
而不同的网络架构下,对应着不同的连接需求,这就要求供应开发多样化的DSP产品组合。而Credo当前推出的光DSP产品已完全覆盖了这些应用场景,这些产品包括:
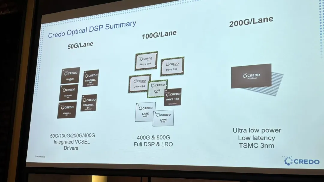
●50G/lane: Seagull系列的光DSP,集成了VCSEL Driver。因低功耗、低成本的优势,在中国市场大受欢迎。Seagull系列非常灵活,可以实现50G、100G、200G和400G的模组,拥有着相当长的生命周期和竞争力,广泛应用于AOC、VR4、SR8等模式。
●100G/lane: Dove系列(第一代)和Lark系列(第二代),分别提供了400G和800G的完整DSP解决方案,满足了不同应用场景的需求。其中,Dove系列可提供Retimer和Gearbox芯片; Lark系列则进一步降低了功耗和延迟,且提供Full DSP和LRO两种方案,供客户针对不同应用场景选择。
●200G/lane: Bluebird系列,采用3nm制程,提供超低功耗、超低延迟的方案,同样提供LRO(功耗可低于20W)和Full DSP(功耗低于25W)两种方案。
表面上看,1.6T产品似乎只是速率的又一次提升,然而这背后是技术实力挑战和Credo的信心。在信号链路层面,这意味着每秒有高达1.6万亿个“0”和“1”的信号需经由DSP实时处理,并确保被精准接收、无误传输。这不仅对信号完整性提出极致要求,更是对芯片设计、系统功耗与稳定性的综合考验。面对这一技术高地,Credo有信心与行业最领先的厂商同台竞争,并在1.6T DSP领域赢得成功。
而基于前几代DSP芯片的推出,Credo的光DSP产品之所以备受市场青睐,核心在于其卓越的能效表现。Credo基于代工厂标准工具包,持续投入多年自主研发,构建了其专有的定制化单元与时序架构,从而实现真正的电路优化。即:在确保性能的前提下,将功耗降优化至业界最低水平。以112G/lane芯片为例,同等5nm制程下,Credo芯片功耗较部分竞争对手低30%。在224G/lane产品中,Credo继续凭借相同的定制化技术路径,持续保持功耗优势。
为展现其在多元场景下的灵活适配能力,Credo在OFC、CIOE等国际光通信盛会上,模拟搭建了AI智算中心的组网环境。基于12.8T至51.2T不同厂商的交换机平台,采用统一型号的网卡(NIC),连接四种主流的服务器,并采用来自10家客户的25款光模块与线缆,构建出多模态光互联解决方案,并进行真实业务流量测试。
Credo所交付的,不仅是芯片本身,更是经过客户验证、已批量部署于现网的成熟的芯片解决方案。目前,多家客户已采用Credo芯片量产光模块,并实际应用于其数据中心网络,持续为AI算力基础架构提供可靠运力支撑。
CPO时代,chiplet与AEC的机会
面向CPO(共封装光学)技术的演进,Credo已启动单波400G产品的研发布局。Chris指出,CPO与Chiplet在架构层面具有高度相似性——CPO光引擎的核心部件正是基于Chiplet技术实现。作为Chiplet领域的早期探索者与领军企业之一,Credo已具备扎实的技术积累,若CPO在单波400G阶段实现规模化落地,Credo必将积极参与并发挥关键作用。不过,目前CPO在散热等关键技术环节仍有待突破。因此,Credo当前仍将战略重心置于巩固可插拔光模块市场的既有优势,持续响应客户需求,同步推进下一代单波400G产品的研发进程。
针对“CPO是否会取代AEC”这一问题,Chris认为短期内发生替代的可能性较低。AEC的应用场景已从单一机架(Rack)内互联,扩展至跨多机架互联,其在功耗、可靠性和成本方面的综合优势依然显著,尤其在AI智算网络中价值突出。当前AEC主流方案仍以单波100G/200G为主,但随着技术演进,未来亦有望实现单波400G的AEC产品,进一步延续其在特定场景下的竞争力。



